Fixing and Optimizing the GnuCOBOL Preprocessor
In this post, I will present some work that we did on the GnuCOBOL compiler, the only fully-mature open-source compiler for COBOL. It all started with a bug issued by one of our customers that we fixed by improving the preprocessing pass of the compiler. We later went on and optimised it to get better performances than the initial version.
Supporting the GnuCOBOL compiler has become one of our commercial activities. If you are interested in this project, we have a dedicated website on our SuperBOL offer, a set of tools and services to ease deploying GnuCOBOL in a company to replace proprietary COBOL environments.

Preprocessing and Replacements in COBOL
COBOL was born in 1959, at a time where the science of programming languages was just starting. If you had to design a new language for the same purpose today, the result would be very different, you would do different mistakes, but maybe not fewer. Actually, COBOL has shown to be particularly resilient to time, as it is still used, 70 years later! Though it has evolved over the years (the last ISO standard for COBOL was released in January 2023), the kernel of the language is still the same, showing that most of the initial design choices were not perfect, but still got the job done.
One of these choices, which would sure scare off young developers, is how COBOL favors code reusability and sharing, through replacements done in its preprocessor.
Let's consider this COBOL code, this will be our example for the rest of this article:
DATA DIVISION.
WORKING-STORAGE SECTION.
01 VAL1.
COPY MY-RECORD REPLACING ==:XXX:== BY ==VAL1==.
01 VAL2.
COPY MY-RECORD REPLACING ==:XXX:== BY ==VAL2==.
01 COUNTERS.
05 COUNTER-NAMES PIC 999 VALUE 0.
05 COUNTER-VALUES PIC 999 VALUE 0.
We are using the free format, a modern way of formatting code, the
older fixed format would require to leave a margin of 7 characters
on the left. We are in the DATA division, the part of the program
that defines the format of data, and specifically, in the
WORKING-STORAGE section, where global variables are defined. In
standard COBOL, there are no local variables, so the
WORKING-STORAGE section usually contains all the variables of the
program, even temporary ones.
In COBOL, there are variables of basic types (integers and strings
with specific lengths), and composite types (arrays and
records). Records are defined using levels: global variables are at
level 01 (such as VAL1, VAL2 and COUNTERS in our example),
whereas most other levels indicate inner fields: here,
COUNTER-NAMES and COUNTER-VALUES are two direct fields of
COUNTERS, as shown by their lower level 05 (both are actually
integers of 3 digits as specified by PIC 999). Moreover, COBOL
programmers like to be able to access fields directly, by making them
unique in the program: it is thus possible to use COUNTER-NAMES
everywhere in the program, without refering to COUNTERS itself
(note that if the field wasn't assigned a unique name, it would be possible
to use COUNTER-NAMES OF COUNTERS to disambiguate them).
On the other hand, in older versions of COBOL, there were no type definitions.
So how would one create two record variables with the same content?
One
would use the preprocessor to include the same file several times,
describing the structure of the record into your program. One would
also use that same file to describe the format of some
data files storing such records. Actually, COBOL developers use
external tools that are used to manage data files and generate the
descriptions, that are then included into COBOL programs in order to manipulate the files
(pacbase for example is one such tool).
In our example, there would be a file MY-RECORD.CPY (usually called
a copybook), containing something like the following somewhere in the
filesystem:
05 :XXX:-USERNAME PIC X(30).
05 :XXX:-BIRTHDATE.
10 :XXX:-BIRTHDATE-YEAR PIC 9999.
10 :XXX:-BIRTHDATE-MONTH PIC 99.
10 :XXX:-BIRTHDATE-MDAY PIC 99.
05 :XXX:-ADDRESS PIC X(100).
This code except is actually not really correct COBOL code because
identifiers cannot contain a :XXX: part:. It was written
instead for it to be included and modified in other COBOL programs.
Indeed, the following line will include the file and perform a replacement of a
:XXX: partial token by VAL1:
COPY MY-RECORD REPLACING ==:XXX:== BY ==VAL1==.
So, in our main example, we now have two global record variables
VAL1 and VAL2, of the same format, but containing fields with
unique names such as VAL1-USERNAME and VAL2-USERNAME.
Allow me to repeat that, despite pecular nature, these features have stood the test of the time.
The journey continues. Suppose now that you are in a specific part
of your program, and that wish to manipulate longer names, say, you
would like the :XXX:-USERNAME variable to be of size 60 instead of 30.
Here is how you could do it:
[...]
REPLACE ==PIC X(30)== BY ==PIC X(60)==.
01 VAL1.
COPY [...]
REPLACE OFF.
01 COUNTERS.
[...]
Here, we can replace a list of consecutive tokens PIC X(30) by
another list of tokens PIC X(60). The result is that the fields
VAL1-USERNAME and VAL2-USERNAME are now 60 bytes long.
REPLACE and COPY REPLACING can both perform the same kind of
replacements on both parts of tokens (using LEADING or TRAILING
keywords) and lists of tokens. COBOL programmers combine them to
perform their daily job of building consistent software, by sharing
formats using shared copybooks.
Let's see now how GnuCOBOL can deal with that.
Preprocessing in the GnuCOBOL Compiler
The GnuCOBOL compiler is a transpiler: it translates COBOL source code into C89 source code, that can then be compiled to executable code by a C compiler. It has two main benefits: high portability, as GnuCOBOL will work on any platform with any C compiler, including very old hardware and mainframes, and simplicity, as code generation is reduced to its minimum, most of the code of the compiler is its parser... Which is actually still huge as COBOL is a particularly rich language.
GnuCOBOL implements many dialects, (i.e.: extensions of COBOL available on proprietary compilers such as IBM, MicroFocus, etc.), in order to provide a solution to the migration issues posed by proprietary platforms.
The support of dialects is one of the most interesting features of GnuCOBOL: by supporting natively many extensions of proprietary compilers, it is possible to migrate applications from these compilers to GnuCOBOL without modifying the sources, allowing to run the same code on the old platform and the new one during all the migration.
One of OCamlPro's main contributions to GnuCOBOL has been to create such a dialect for GCOS7, a former Bull mainframe still in use in some places.

To perform its duty, GnuCOBOL processes COBOL source files in two passes: it preprocesses them during the first phase, generating a new temporary COBOL file with all inclusions and replacement done, and then parses this file and generates the corresponding C code.
To do that, GnuCOBOL includes two pairs of lexers and parsers, one for each
phase. The first pair only recognises a very limited set of constructions, such
as COPY... REPLACING, REPLACE, but also some
other ones like compiler directives.
The lexer/parser for preprocessing directly works on the input file,
and performed all these operations in a single pass before version
3.2.
The output can be seen using the -E argument:
$ cobc -E --free foo.cob
#line 1 "foo.cob"
DATA DIVISION.
WORKING-STORAGE SECTION.
01 VAL1.
#line 1 "MY-RECORD.CPY"
05 VAL1-USERNAME PIC X(60).
05 VAL1-BIRTHDATE.
10 VAL1-BIRTHDATE-YEAR PIC 9999.
10 VAL1-BIRTHDATE-MONTH PIC 99.
10 VAL1-BIRTHDATE-MDAY PIC 99.
05 VAL1-ADDRESS PIC X(100).
#line 5 "foo.cob"
01 VAL2.
#line 1 "MY-RECORD.CPY"
05 VAL2-USERNAME PIC X(60).
05 VAL2-BIRTHDATE.
10 VAL2-BIRTHDATE-YEAR PIC 9999.
10 VAL2-BIRTHDATE-MONTH PIC 99.
10 VAL2-BIRTHDATE-MDAY PIC 99.
05 VAL2-ADDRESS PIC X(100).
#line 7 "foo.cob"
01 COUNTERS.
05 COUNTER-NAMES PIC 999 VALUE 0.
05 COUNTER-VALUES PIC 999 VALUE 0.
The -E option is particularly useful if you want to understand the
final code that GnuCOBOL will compile. You can also get access to this
information using the option --save-temps (save intermediate files),
in which case cobc will generate a file with extension .i (foo.i
in our case) containing the preprocessed COBOL code.
You can see that cobc successfully performed both the REPLACE and
COPY REPLACING instructions.
The corresponding code in version
3.1.2
is in file cobc/pplex.l, function ppecho. Fully understanding it
is left as an exercice for the motivated reader.
The general idea is that replacements defined by COPY REPLACING and REPLACE
are added to the same list of active replacements.
We show in the next section that such an implementation does not conform to the ISO standard.
Conformance to the ISO Standard
You may wonder if it is possible for REPLACE statements to perform
replacements that would change a COPY statement, such as :
REPLACE ==COPY MY-RECORD== BY == COPY OTHER-RECORD==.
COPY MY-RECORD.
You may also wonder what happens if we try to combine replacements by
COPY and REPLACE on the same tokens, for example:
REPLACE ==VAL1-USERNAME PIC X(30)== BY ==VAL1-USERNAME PIC X(60)==
Such a statement only makes sense if we assume the COPY replacements
have been performed before the REPLACE replacements are performed.
Such ambiguities have been resolved in the ISO Standard for COBOL: in
section 7.2.1. Text Manipulation >> General, it is specified that
preprocessing is executed in 4 phases on the streams of tokens:
1. `COPY` statements are performed, and the corresponding `REPLACING`
replacements too;
2. Conditional compiler directives are then performed;
3. `REPLACE` statements are performed;
4. `COBOL-WORDS` statements are performed (allowing to enabled/disable
some keywords)
So, a REPLACE cannot modify a COPY statement (and the opposite is
also impossible, as REPLACE are not allowed in copybooks), but it
can modify the same set of tokens that are being modified by the
REPLACING part of a COPY.

As described in the previous section, GnuCOBOL implements all phases
1, 2 and 3 in a single one, even mixing replacements defined by
COPY and by REPLACE statements. Fortunately, this behavior is good
enough for most programs. Unfortunately, there are still programs
that combine COPY and REPLACE on the same tokens, leading to hard
to debug errors, as the compiler does not conform to the
specification.
A difficult situation which happened to one of our customers and that we prompty addressed by patching a part of the compiler.
Preprocessing with Automata on Streams
Correctly implementing the specification written in the standard would make the preprocessing phase quite complicated. Indeed, we would have to implement a small parser for every one of the four steps of preprocessing. That's actually what we did for our COBOL parser in OCaml used by the LSP (Language Server Protocol) of our SuperBOL Studio COBOL plugin for VSCode.
However, doing the same in GnuCOBOL is much harder: GnuCOBOL is
written in C, and such a change would require a complete rewriting of
the preprocessor, something that would take more time than we
had on our hands. Instead, we opted for rewriting the replacement function, to
split COPY REPLACING and REPLACE into two different replacement phases.
The corresponding C
code
has been moved into a file cobc/replace.c. It implements an
automaton that applies a list of replacements on a stream of tokens,
returning another stream of tokens. The preprocessor is thus composed
of two instances of this automaton, one for COPY REPLACING
statements and another one for REPLACE statements.
The second instance takes the stream of tokens produced by the first one as input. The automaton is implemented using recursive functions, which is particularly suitable to allow reasoning about its correctness. Actually, several bugs were found in the former C implementation while designing this automaton. Each automaton has an internal state, composed of a set of tokens which are queued (and waiting for a potential match) and a list of possible replacements of these tokens.
Thanks to this design, it was possible to provide a working implementation in a very short delay, considering the complexity of that part of the compiler.
We added several tests to the testsuite of the compiler for all the bugs that had been detected in the process to prevent regressions in the future, and the corresponding pull request was reviewed by Simon Sobisch, the GnuCOBOL project leader, and later upstreamed.
Some Performance Issues
Unfortunately, it was not the end of the work: Simon performed some performance evaluations on this new implementation, and although it had improved the conformance of GnuCOBOL to the standard, it did affect the performance negatively.
Compiler performance is not always critical for most applications, as
long as you compile only individual COBOL source files. However, some
source files can become very big, especially when part of the code is
auto-generated. In COBOL, a typical case of that is the use of a
pre-compiler, typically for SQL. Such programs contain EXEC SQL
statements, that are translated by the SQL pre-compiler into much
longer COBOL code, consisting mostly of CALL statements calling C
functions into the SQL library to build and execute SQL requests.
For such a generated program, of a whopping 700 kLines, Simon noticed an important degradation in compilation time, and profiling tools concluded that the new preprocessor implementation was responsible for it, as shown in the flamegraph below:
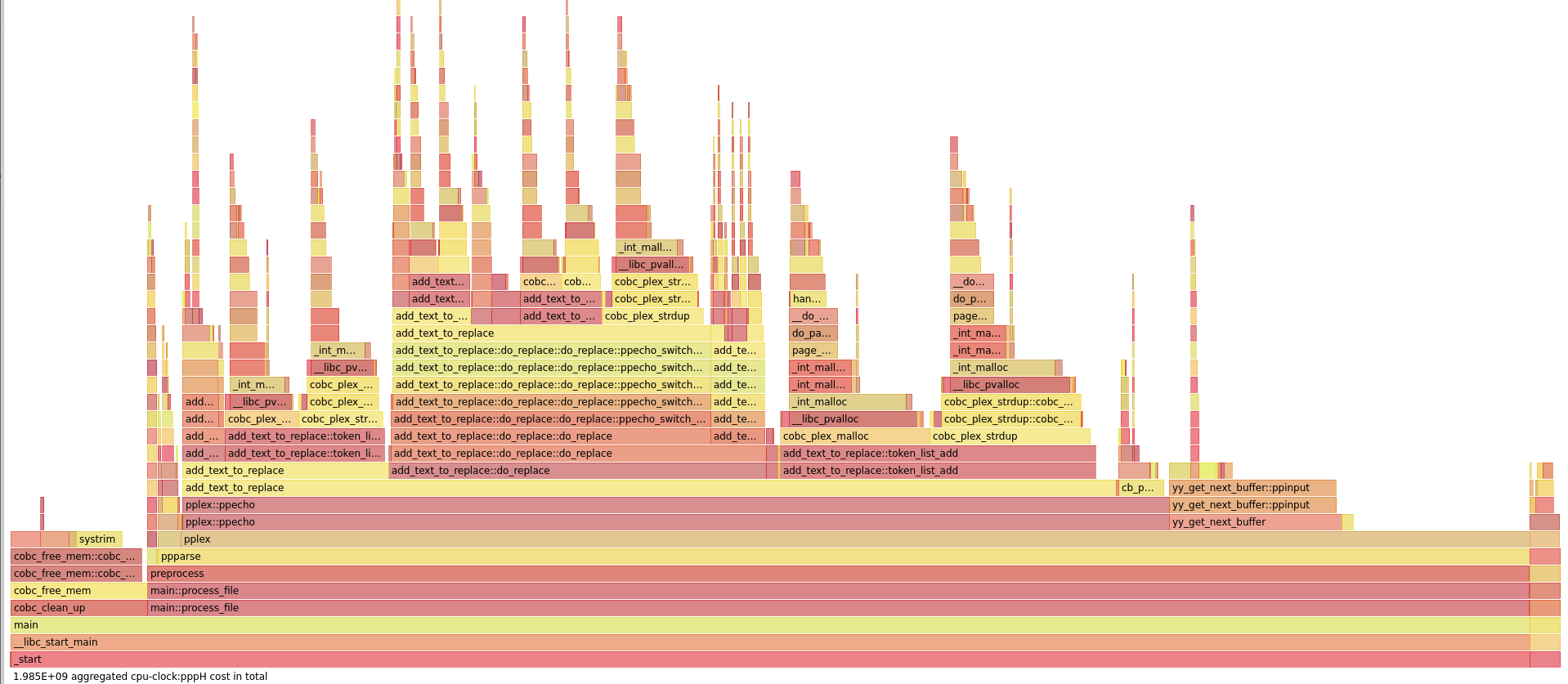
perf stats visualised on hotspot: the horizontal axis
is the total duration. We can see that ppecho, the function for
replacements, takes most of the preprocessing time, with the
two-automata replacement phases. Credit: Simon Sobisch
So we started investigating to fix the problem in a new pull-request.
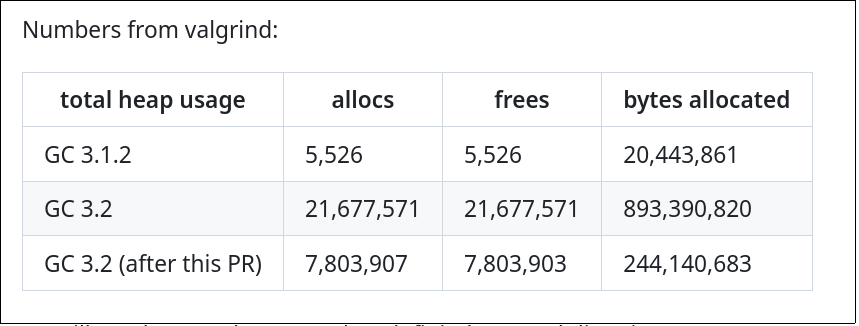
Optimizing Allocations
Our first intuition was that the main difference with the previous implementation came from allocating too many lists in the temporary state of the two automatons. This intuition was only partially right, as we will see.
Mutable lists were used in the automaton (and also in the former implementation) to store a small part of the stream of tokens, while they were being matched with a replacement source. On a partial match, the list had to wait for additionnal tokens to check for a full match. Actually, these lists were used as queues, as tokens were always added at the end, while matched or un-matched tokens were removed from the top. Also, the size of these lists was bounded by the maximal replacement that was defined in the code, that would unlikely be more than a few dozen tokens.
Our first idea was to replace these lists by real queues, that can be efficiently implemented using circular buffers and arrays. Each and every allocation of a new list element would then be replaced by the single allocation of a circular buffer, granted with a few possible reallocations further down the road if the list of replacements was to grow bigger.
The results were a bit disappointing: on the flamegraph, there was some improvement, but the replacement phase still took a lot of time:
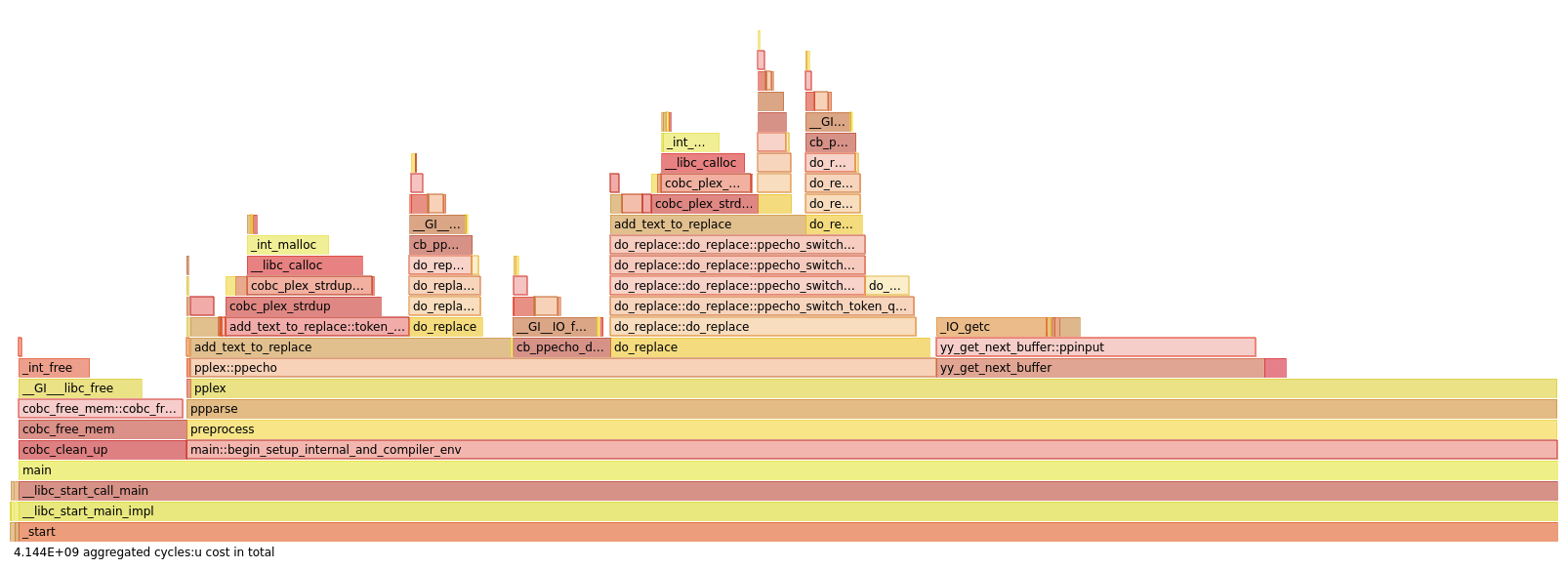
token_list_add. But our work is not yet finished! Credit: Simon Sobisch
Another intuition we had was that we had been a bit naive
about allocating tokens: in the initial implementation of version
3.1.2, tokens were allocated when copied from the lexer into the
single queue for replacement; in our implementation, that job was also
done, but twice, as they were allocated in both automata. So, we
modified our implementation to only allocate tokens when they are
first entered in the COPY REPLACING stream, and not anymore when
entering the REPLACE stream. A simple idea, that reduced again the
remaining allocations by a factor of 2.
Yet, the new optimised implementation still didn't match the
performance of the former 3.1.2 version, and we were running out of
ideas on how the allocations performed by the automata could again be
improved:
What about Fast Paths ?
So we decided to study some of the code from 3.1.2 to understand what
could cause such a difference, and it became immediately obvious: the
former version had two fast paths, that we had left out of our own
implementation!
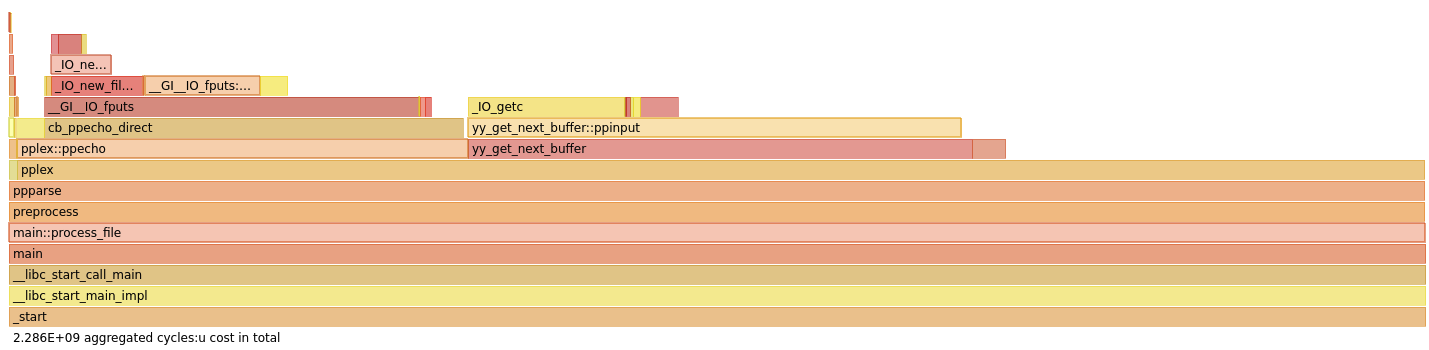
The two fast paths that completely shortcut the replacement mechanisms are the following:
The first one is when there are no replacements defined in the source. In
COBOL, most replacements are only performed in the DATA DIVISION, and
moreover, COPY REPLACING ones are only performed during copies. This means
that a large part of the code that did not need to go through our two automata
still did!
The second fast path is for spaces: replacements always start and finish by a non-space token in COBOL, so, if we check that we are not in the middle of partial match (i.e. both internal token queues are empty), we can safely make the space token skip the automata. Again, given the frequency of space tokens (about half, as there are very few other separators), this fast path is likely to be used very, very frequently.
Implementing them was straigthforward, and the results were the one expected:
Conclusion
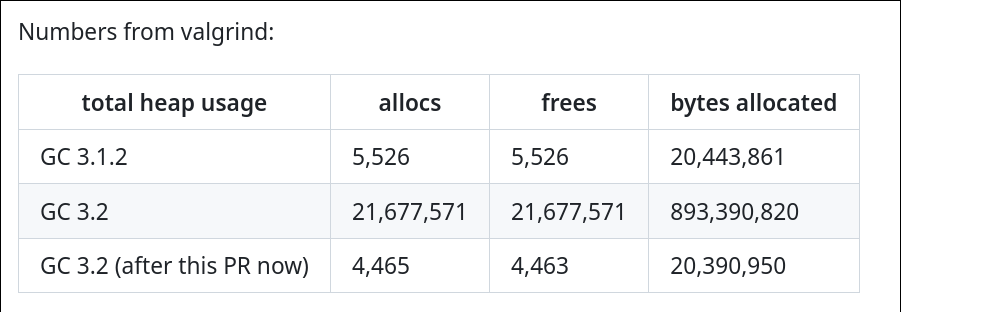
As often with optimisations, intuitions do not always lead to the expected improvements: in our case, the real improvement came not with improving the algorithm, but from shortcutting it!
Yet, we are still very pleased by the results: the new optimised
implementation of replacements in GnuCOBOL makes it more conformant to the
standard, and also more efficient than the former 3.1.2 version, as shown by
the final results sent to us by Simon:
Au sujet d'OCamlPro :
OCamlPro développe des applications à haute valeur ajoutée depuis plus de 10 ans, en utilisant les langages les plus avancés, tels que OCaml, Rust, et WebAssembly (Wasm) visant aussi bien rapidité de développement que robustesse, et en ciblant les domaines les plus exigeants (méthodes formelles, cybersécurité, systèmes distribués/blockchain, conception de DSLs). Fort de plus de 20 ingénieurs R&D, avec une expertise unique sur les langages de programmation, aussi bien théorique (plus de 80% de nos ingénieurs ont une thèse en informatique) que pratique (participation active au développement de plusieurs compilateurs open-source, prototypage de la blockchain Tezos, etc.), diversifiée (OCaml, Rust, Cobol, Python, Scilab, C/C++, etc.) et appliquée à de multiples domaines. Nous dispensons également des [formations sur mesure certifiées Qualiopi sur OCaml, Rust, et les méthodes formelles] (https://training.ocamlpro.com/) Pour nous contacter : contact@ocamlpro.com.
Articles les plus récents
2025
2024
- opam 2.3.0 release!
- Optimisation de Geneweb, 1er logiciel français de Généalogie depuis près de 30 ans
- Alt-Ergo 2.6 is Out!
- Flambda2 Ep. 3: Speculative Inlining
- opam 2.2.0 release!
- Flambda2 Ep. 2: Loopifying Tail-Recursive Functions
- Fixing and Optimizing the GnuCOBOL Preprocessor
- OCaml Backtraces on Uncaught Exceptions
- Opam 102: Pinning Packages
- Flambda2 Ep. 1: Foundational Design Decisions
- Behind the Scenes of the OCaml Optimising Compiler Flambda2: Introduction and Roadmap
- Lean 4: When Sound Programs become a Choice
- Opam 101: The First Steps
2023