Tutoriel Format
Article écrit par Mattias.
Le module Format d’OCaml est un module extrêmement puissant mais malheureusement très mal utilisé. Il combine notamment deux éléments distincts :
- les boîtes d’impression élégante
- les tags sémantiques
Le présent article vise à démystifier une grande partie de ce module afin de découvrir l’ensemble des choses qu’il est possible de faire avec.
Si tout va bien vous devriez passer de
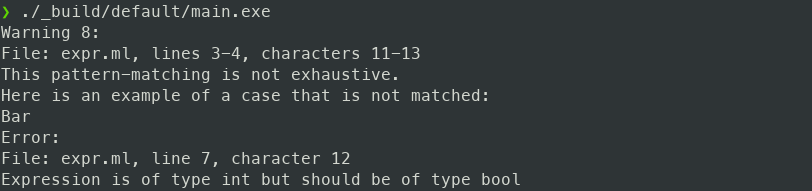
à
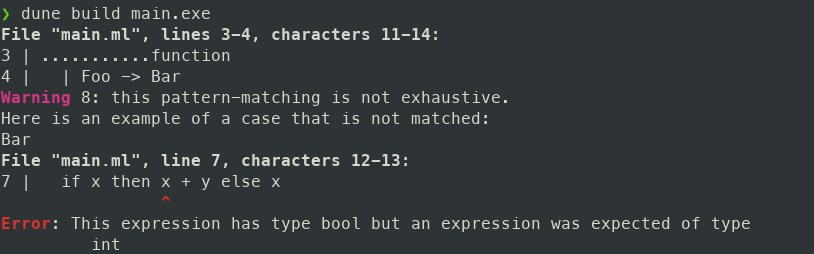
(En réalité nous arriverons à un résultat légèrement différent car l’auteur de ce tutoriel n’aime pas tous les choix faits pour afficher les messages d’erreur en OCaml mais les différences n’auront pas de grande importance)
I. Introduction générale : fprintf fmt "%a" pp_error e
Si vous ne comprenez pas ce que le code dans le titre doit faire, je vous invite à lire attentivement ce qui va suivre. Sinon vous pouvez directement sauter à la deuxième partie.
I.1. Rappels sur printf
Pour rappel, la fonction printf est une fonction variadique (c’est-à-dire qu’elle peut prendre un nombre variable de paramètres).
-
Le premier paramètre est une chaîne de formattage composée de caractères et de spécificateurs de format.
- Les caractères sont affichés tels quels.
printf "abc"afficheraabc. - Les spécificateurs de caractère sont des caractères précédés du caractère
%(syntaxe héritée du C). Ils sont remplacés à l’exécution par un des paramètres fournis après la chaîne de formattage à la fonction et servent à indiquer de quel type doit être la valeur qui sera affichée (ainsi que d’autres informations dont les détails peuvent être trouvés dans la documentation du module Printf.printf "Test: %d"attend un entier signé et afficheraTest: <d>avec<d>remplacé par l’entier fourni.
- Les caractères sont affichés tels quels.
-
Les paramètres suivants sont les valeurs fournies à
printfpour remplacer les spécificateurs de formatprintf "%d %s %c" 3 s 'a'affichera l’entier signé 3, une espace insécable, le contenu de la variablesqui doit être une chaîne de caractères, une autre espace insécable et finalement le caractère ‘a’.- On remarque aussi qu’ici le nombre de paramètres supplémentaires fournis en plus de la chaîne de formattage correspond au nombre de spécificateurs et que ceux-ci ne peuvent être intervertis.
printf "%d %c" 'a' 3ne pourra pas être compilé/exécuté car%dattend un entier signé et le premier paramètre est un caractère. Les spécificateurs qui n’attendent qu’un argument sont des spécificateurs que j’appelle unaires et sont extrêmement faciles à utiliser, il faut seulement savoir quel caractère correspond à quel type et les donner dans le bon ordre comme illustré dans la figure ci-dessous (le chevron représentant la sortie standard)
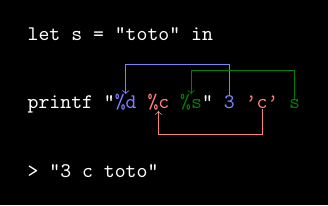
I.2. Afficher un type défini par l’utilisateur
Arrive alors ce moment où vous commencez à définir vos propres structures de données et, malheureusement, il n’y a aucun moyen d’afficher votre expression avec les spécificateurs par défaut (ce qui semble normal). Définissons donc notre propre type et affichons-le avec les techniques déjà vues :
type error =
| Type_Error of string * string
| Apply_Non_Function of string
let pp_error = function
| Type_Error (s1, s2) -> printf "Type is %s instead of %s" s1 s2
| Apply_Non_Function s -> printf "Type is %s, this is not a function" s
Supposons maintenant que nous ayons une liste d’erreurs et que nous souhaitions les afficher en les séparant par une ligne horizontale. Une première solution serait la suivante :
let pp_list l =
List.iter (fun e ->
pp_error e;
printf "\n"
) l
Cette façon de faire a plusieurs inconvénients (qui vont être magiquement réglés par la fonction du titre).
I.3. Afficher sur un formatter abstrait
Le premier inconvénient est que printf envoie son résultat vers la sortie standard alors qu’on peut vouloir l’envoyer vers un fichier ou vers la sortie d’erreur, par exemple.
La solution est fprintf (il serait de bon ton de feindre la surprise ici).
fprintf prend un paramètre supplémentaire avant la chaîne de formattage appelé formatter abstrait. Ce paramètre est du type formatter et représente un imprimeur élégant (ou pretty-printer)
c’est-à-dire l’objet vers lequel le résultat devra être envoyé. L’énorme avantage qui en découle est qu’on peut transformer beaucoup de choses en formatter. Un fichier, un buffer, la sortie standard etc. À vrai dire, printf est implémenté comme let printf = fprintf std_formatter
Pour l’utiliser on va donc modifier pp_error et lui donner un paramètre supplémentaire :
let pp_error fmt = function
| Type_Error (s1, s2) -> fprintf fmt "Type is %s instead of %s" s1 s2
| Apply_Non_Function s -> fprintf fmt "Type is %s, this is not a function" s
Puis on réécrit pp_list pour prendre cela en compte :
let pp_list fmt l =
List.iter (fun e ->
pp_error fmt e;
fprintf fmt "\n"
) l
Comme on peut le voir dans la figure ci-dessous, fprintf imprime dans le formatter qui lui est fourni en paramètre et non plus sur la sortie standard.
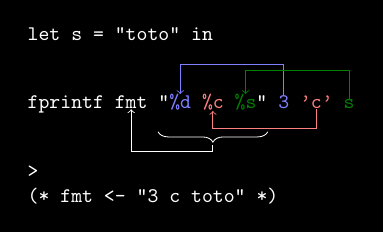
Si on veut maintenant afficher le résultat sur la sortie standard il suffira simplement de donner pp_list std_formatter comme formatter à fprintf. Cette façon de faire n’a, en réalité, que des avantages, puisqu’elle permet d’être beaucoup plus fexible quant au formatter qui sera utilisé à l’exécution du programme.
I.4. Afficher des types complexes avec %a
Le deuxième problème arrivera bien assez vite si nous continuons avec cette méthode. Pour bien le comprendre, reprenons pp_error. Dans le cas de Type_error of string * string on veut écrire Type is s1 instead of s2 et on fournit donc à fprintf la chaîne de formattage "Type is %s instead of %s" avec s1 et s2 en paramètres supplémentaires. Comment devrions-nous faire si s1 et s2 étaient des types définis par l’utilisateur avec chacun leur fonction d’affichage pp_s1`` : formatter -> s1 -> unit et pp_s2 : formatter -> s2 -> unit ? En suivant la logique de notre solution jusqu’ici, nous écririons le code suivant :
let pp_error fmt = function
| Type_Error (s1, s2) ->
fprintf fmt "Type is ";
pp_s1 fmt s1;
fprintf fmt "instead of ";
pp_s2 fmt s2
| Apply_non_function s -> fprintf fmt "Type is %s, this is not a function" s
Il est assez facile de se rendre compte rapidement que plus nous devrons manipuler des types complexes, plus cette syntaxe s’alourdira. Tout cela parce que les spécificateurs de caractère unaires ne permettent de manipuler que les types de base d’OCaml.
C’est là qu’entre en jeu %a. Ce spécificateur de caractère est, lui, binaire (ternaire en réalité mais un de ses paramètres est déjà fourni). Ses paramètres sont :
- Une fonction d’affichage de type
formatter -> 'a -> unit(premier paramètre devant être fourni) - Le
formatterdans lequel il doit afficher son résultat (qui ne doit pas être fourni en plus) - La valeur qu’on souhaite afficher
Il appliquera ensuite le formatter et la valeur à la fonction fournie comme premier argument et lui donner la main pour qu’elle affiche ce qu’elle doit dans le formatter qui lui a été fourni en paramètre. Lorsqu’elle aura terminé, l’impression continuera. L’exemple suivant montre le fonctionnement (avec une impression sur la sortie standard, fmt ayant été remplacé par std-formatter

Dans notre cas nous avions déjà transformé nos fonctions d’affichage pour qu’elles prennent un formatter abstrait et nous n’avons donc presque rien à modifier :
let pp_error fmt = function
| Type_Error (s1, s2) -> fprintf fmt "Type is %s instead of %s" s1 s2
| Apply_Non_Function s -> fprintf fmt "Type is %s, this is not a function" s
let pp_list fmt l =
List.iter (fun e ->
fprintf fmt "%a\n" pp_error e;
) l
Et, bien sûr, si s1 et s2 avaient eu leurs propres fonctions d’affichage :
let pp_error fmt = function
| Type_Error (s1, s2) -> fprintf fmt "Type is %a instead of %a" pp_s1 s1 pp_s2 s2
| Apply_Non_Function s -> fprintf fmt "Type is %s, this is not a function" s
Arrivé-e-s ici vous devriez être à l’aise avec les notions de formatter abstrait et de spécificateur de caractère binaire et vous devriez donc pouvoir afficher n’importe quelle structure de donnée, même récursive, sans aucun soucis. Je recommande vivement cette façon de faire afin que tout changement qui devrait succéder ne nécessite pas de changer l’intégralité du code.
II. Les boîtes d’impression élégante
Et pour justement avoir des changements qui ne nécessitent pas de tout modifier, il va falloir s’intéresser un minimum aux boîtes d’impression élégante.
Aussi appelées pretty-print boxes, je les appellerai “boîtes” dorénavant, un tutoriel existe déjà, fait par l’équipe de la bibliothèque standard.
L'idée derrière les boîtes est tout simple :
À mon niveau je m’occupe correctement de comment afficher mes éléments et je n’impose rien au-dessus.
Reprenons, par exemple, la fonction permettant d’afficher les error:
let pp_error fmt = function
| Type_Error (s1, s2) -> fprintf fmt "Type is %s instead of %s" s1 s2
| Apply_Non_Function s -> fprintf fmt "Type is %s, this is not a function" s
Si on ajoutait un retour à la ligne on imposerait à toute fonction nous appelant ce saut de ligne or ce n’est pas à nous d’en décider. Cette fonction, en l’état, fait parfaitement ce qu’elle doit faire.
Regardons, par contre, la fonction affichant une liste d’erreur :
let pp_list fmt l =
List.iter (fun e ->
fprintf fmt "%a\n" pp_error e;
) l
A l’issue de celle-ci un saut à ligne provenant du dernier élément est forcé. Non seulement il n’est pas recommandé d’utiliser n (ou @n ou même @.) car ce ne sont pas à proprement parler des directives de Format mais des directives systèmes qui vont donc chambouler le reste de l’impression.
Malheureusement bien trop de développeurs et développeuses ont découvert
@.en même temps queFormatet s’en servent sans restriction. Au risque de me répéter souvent : n’utilisez pas@.!
II.1. Le spécificateur @
On l’avait vu, une chaîne de formattage est composée de caractères et de spécificateurs de caractères commençant par % Les spécificateurs sont des caractères qui ne sont pas affichés et qui seront remplacés avant l’affichage final.
Format ajoute son propre spécificateur de caractère : @.
II.1.a. Le vidage (flush)
La première spécification qu’on a vue est donc celle qu’il ne faut presque jamais utiliser (ce qui pose la question de l’avoir mentionnée en premier lieu) : @.. Cette spécification indique seulement au moteur d’impression qu’à ce niveau là il faut sauter une ligne et vider l’imprimeur. Les deux autres spécifications semblables sont @n qui n’indique que le saut de ligne et @? qui n’indique que le vidage de l’imprimeur. L’inconvénient de ces trois spécificateurs est qu’ils sont trop puissants et chamboulent donc le bon fonctionnement du reste de l’impression. Je n’ai personnellement jamais utilisé @n (autant utiliser une boîte avec un spécificateur de coupure comme nous le verrons immédiatement après) et n’utilise @. que lorsque je sais qu’il ne reste rien à imprimer.
II.1.b. Les indications de coupure ou d’espace
Important :
- Une indication de coupure saute à la ligne s’il le faut sinon elle ne fait rien
- Une indication d’espace sécable saute à la ligne s’il le faut, sinon elle affiche une espace
Les deux sont donc des indications de saut de ligne si nécessaire, il
n’existe pas d’indication d’espace par défaut ou rien s’il n’y a pas
assez d’espace (utiliser affichera toujours une espace).
Les indications sont au nombre de trois (et leur fonctionnement sera bien plus clair lorsque vous verrez les boîtes) :
@,: indication de coupure (c’est-à-dire rien prioritairement ou un saut à la ligne s’il le faut)@⎵: indique une espace sécable (c’est-à-dire une espace prioritairement ou un saut à la ligne s’il le faut) (Il faut bien évidemment comprendre le caractère⎵comme l’espace blanc habituel)@;<n o>: indiquenespaces sécables ou une coupure indentée deo(c’est-à-direnespaces sécables prioritairement ou un saut à la ligne avec une indentation supplémentaire deos’il le faut)
D’après ce que je viens d’écrire il devrait être évident maintenant que le caractère est une espace insécable qui ne provoquera donc pas de saut à la ligne quand bien même on dépasserait les limites de celle-ci. Contrairement à nos espaces de traitement de texte habituel qui sont des espaces sécables (pouvant provoquer des sauts de ligne), il faut spécifier quels espaces sont sécables lorsqu’on utilise Format.
On écrira par exemple fprintf fmt "let rec f =@ %a" pp_expr e car on ne veut pas que let rec f = soit séparé en plusieurs lignes mais on met bien @⎵ avant %a car l’expression sera soit sur la même ligne si suffisament petite soit à la ligne suivante si trop grande (on devrait même écrire @;<1 2> pour que l’expression soit indentée si on saute à la ligne suivante mais, on va le voir immédiatement, c’est là que les boîtes nous permettent d’automatiser ce genre de comportement)
II.1.c. Les boîtes
La deuxième spécification est celle permettant d’ouvrir et de fermer des boîtes.
Une boîte se commence par @[ et se termine par @]. Entre ces deux bornes, on fait ce qu’on veut (sauf utiliser @., @? ou @\n !). Tout ce qui se passe à l’intérieur de la boîte reste (et doit rester) à l’intérieur de celle-ci. Indentation, coupures, boîtes verticales, horizontales, les deux, l’une ou l’autre, toutes ces options sont accessibles une fois qu’une boîte a été ouverte. Voyons-les rapidement (pour rappel, la version détaillée est disponible dans le tutoriel.
Une fois qu’une boîte a été ouverte on peut préciser entre deux chevrons le comportement qu’on veut qu’elle ait en cas d’indication de coupure, en voici un rapide aperçu :
<v>: Toute indication de coupure entraîne un saut à la ligne<h>: Toute indication d’espace entraîne une espace, les indications de coupure n’ont aucun effet<hv>: Si toute la boîte peut être imprimée sur la même ligne alors seules les indications d’espace sont prises en compte sinon seules les indications de coupure le sont et chaque élément est imprimé sur sa propre ligne<hov>: Tant que des éléments peuvent être imprimés sur une ligne ils le sont avec leurs indications d’espace. Les indications de coupure sont utilisées lorsqu’il faut sauter une ligne.
Chacun de ces comportements peut se voir attribuer une valeur supplémentaire, sa valeur d’indentation, qui indique l’indentation par rapport au début de la boîte qui devra être ajoutée à chaque saut de ligne.
Soit le code suivant permettant d’afficher une liste d’items séparés soit par une indication de coupure @,, soit par une indication d’espace @⎵ soit par une indication d’espace ou de coupure indentée @;<2 3> (2 espaces ou une coupure indentée de trois espaces) :
open Format
let l = ["toto"; "tata"; "titi"]
let pp_item fmt s = fprintf fmt "%s" s
let pp_cut fmt () = fprintf fmt "@,"
let pp_spc fmt () = fprintf fmt "@ "
let pp_brk fmt () = fprintf fmt "@;<2 3>"
let pp_list pp_sep fmt l =
pp_print_list pp_item ~pp_sep fmt l
Voici un récapitulatif des différents comportements de boîtes en fonction des indications de coupure/espace rencontrées :
(* Boite verticale (tout est coupure) *)
printf "------------@.";
printf "v@.";
printf "------------@.";
printf "@[<v 2>[%a]@]@." (pp_list pp_cut) l;
printf "@[<v 2>[%a]@]@." (pp_list pp_spc) l;
printf "@[<v 2>[%a]@]@." (pp_list pp_brk) l;
(* Sortie attendue:
------------
v
------------
[toto
tata
titi]
[toto
tata
titi]
[toto
tata
titi]
*)
(* Boîte horizontale (pas de coupure) *)
printf "------------@.";
printf "h@.";
printf "------------@.";
printf "@[<h 2>[%a]@]@." (pp_list pp_cut) l;
printf "@[<h 2>[%a]@]@." (pp_list pp_spc) l;
printf "@[<h 2>[%a]@]@." (pp_list pp_brk) l;
(* Sortie attendue:
------------
h
------------
[tototatatiti]
[toto tata titi]
[toto tata titi]
*)
(* Boîte horizontale-verticale
(Affiche tout sur une ligne si possible sinon boîte verticale) *)
printf "------------@.";
printf "hv@.";
printf "------------@.";
printf "@[<hv 2>[%a]@]@." (pp_list pp_cut) l;
printf "@[<hv 2>[%a]@]@." (pp_list pp_spc) l;
printf "@[<hv 2>[%a]@]@." (pp_list pp_brk) l;
(* Sortie attendue:
------------
hv
------------
[toto
tata
titi]
[toto
tata
titi]
[toto
tata
titi]
*)
(* Boîte horizontale ou verticale tassante
(Affiche le maximum possible sur une ligne avant de sauter à la
ligne suivante et recommencer) *)
printf "------------@.";
printf "hov@.";
printf "------------@.";
printf "@[<hov 2>[%a]@]@." (pp_list pp_cut) l;
printf "@[<hov 2>[%a]@]@." (pp_list pp_spc) l;
printf "@[<hov 2>[%a]@]@." (pp_list pp_brk) l;
(* Sortie attendue:
------------
hov
------------
[tototata
titi]
[toto tata
titi]
[toto
tata
titi]
*)
(* Boîte horizontale ou verticale structurelle
(Même fonctionnement que la boîte tassante sauf pour le dernier
retour à la ligne qui tente de favoriser une indentation de
niveau 0) *)
printf "------------@.";
printf "b@.";
printf "------------@.";
printf "@[<b 2>[%a]@]@." (pp_list pp_cut) l;
printf "@[<b 2>[%a]@]@." (pp_list pp_spc) l;
printf "@[<b 2>[%a]@]@." (pp_list pp_brk) l
(* Sortie attendue:
------------
b
------------
[tototata
titi]
[toto tata
titi]
[toto
tata
titi]
*)
Petite précision sur l’utilisation ici des @. alors qu’il est recommandé de ne jamais les utiliser. Il ne faut en réalité pas jamais les utiliser, il faut seulement les utiliser lorsqu’on est sûr de n’être dans aucune boîte. Ici, par exemple, on souhaite marquer distinctement les différentes impressions de boîtes, il est donc tout à fait correct d’utiliser @. étant donné qu’on est sûr d’être au dernier niveau d’impression (rien au-dessus) et de ne pas casser une passe d’impression élégante. Il serait donc bien plus précis de dire
Il ne faut pas utiliser
@.,@net@?dans des impressions qui sont ou seront potentiellement imbriquées
Mais il est bien plus simple pour commencer de ne jamais les utiliser quitte à les rajouter après.
Le comportement de la boîte b (boîte structurelle) semble être le même que celui de la boîte hov (boîte tassante) mais il se trouve des cas où les deux diffèrent (généralement lorsqu’un saut de ligne réduit l’indentation courante, la boîte structurelle saute à la ligne même s’il reste de la place sur la ligne courante). Je vous invite à consulter le tutoriel pour plus de précisions (je dois aussi avouer que leur fonctionnement est très proche de ce qu’on pourrait appeler “opaque” étant donné qu’en fonction de la taille de marge le comportement attendu aura lieu ou non. L’auteur de ce tutoriel tient à préciser qu’il utilise plutôt des boîtes verticales avec une indentation nulle s’il lui arrive de vouloir obtenir le comportement des boîtes structurelles, un exemple est fourni lors de l’affichage en HTML à la fin de ce document).
II.2. Récapitulatif
- Il faut utiliser des boîtes
- Les indications de vidage fermant toutes les boîtes, il ne faut surtout pas les utiliser dans des fonctions d’affichage internes, il faut se limiter aux indications de coupure et d’espace
- Il faut vraiment utiliser des boîtes
Vous voilà armé-e-s pour utiliser Format dans sa version la plus simple, avec des boîtes, de l’indentation, des indications de coupure et d’espace.
Reprenons notre affichage d’erreur :
let pp_error fmt = function
| Type_Error (s1, s2) -> fprintf fmt "@[<hov 2>Type is %s@ instead of %s@]" s1 s2
| Apply_non_function s -> fprintf fmt "@[<hov 2>Type is %s,@ this is not a function@]" s
let pp_list fmt l =
pp_print_list pp_error fmt l
On a encapsulé l’affichage des deux erreurs dans des boîtes hov avec une indication d’espace sécable au milieu et utilisé la fonction pp_print_list du module Format
Si je tente maintenant d’afficher une liste d’erreurs dans deux environnements, un de 50 colonnes et l’autre de 25 colonnes de largeur avec le code suivant :
let () =
let e1 = Type_Error ("int", "bool") in
let e2 = Apply_non_function ("int") in
let e3 = Type_Error ("int", "float") in
let e4 = Apply_non_function ("bool") in
let el = [e1; e2; e3; e4] in
pp_set_margin std_formatter 50;
fprintf std_formatter "--------------------------------------------------@.";
fprintf std_formatter "@[<v 0>%a@]@." pp_list el;
pp_set_margin std_formatter 25;
fprintf std_formatter "-------------------------@.";
fprintf std_formatter "@[<v 0>%a@]@." pp_list el;
J’obtiens le résultat suivant :
--------------------------------------------------
Type is int instead of bool
Type is int, this is not a function
Type is int instead of float
Type is bool, this is not a function
-------------------------
Type is int
instead of bool
Type is int,
this is not a function
Type is int
instead of float
Type is bool,
this is not a function
Ce qu’on rajoute en verbosité on le gagne en élégance. Et en parlant d’élégance, ça manque de couleurs.
III. Les tags sémantiques
Cette partie n’est pas présente dans le tutoriel mais dans un article tutoriel qui l’explique assez rapidement.
La troisième spécification, donc (après celles de coupure et de boîtes), est la spécification de tag sémantique : @{ pour en ouvrir un et @} pour le fermer.
III.1. Marquer son texte
Mais avant de comprendre leur fonctionnement, cherchons à comprendre leur intérêt. Que vous souhaitiez afficher dans un terminal, dans une page html ou autre, il y a de fortes chances que cette sortie accepte les marques de texte comme l’italique, la coloration etc. Utilisateur d’emacs et d’un terminal ANSI je peux modifier l’apparence de mon texte grâce aux codes ANSI :

Si je crée un programme OCaml qui affiche cette chaîne de charactère et que je l’exécute directement dans mon terminal je devrais obtenir le même résultat :

Naturellement, ça ne fonctionne pas, si l’informatique était standardisée et si tout le monde savait communiquer ça se saurait. Il s’avère que le caractère 033 est interprété en octal par les terminaux ANSI mais en décimal par OCaml (ce qui semble être l’interprétation normale). OCaml permet de représenter un caractère selon plusieurs séquences d’échappement différentes :
| Séquence | Caractère résultant |
|---|---|
DDD | le caractère correspondant au code ASCII DDD en décimal |
xHH | le caractère correspondant au code ASCII HH en hexadécimal |
oOOO | le caractère correspondant au code ASCII OOO en octal |
On peut donc écrire au choix
let () = Format.printf "\027[36mBlue Text \027[0;3;30;47mItalic WhiteBG Black Text"
let () = Format.printf "\x1B[36mBlue Text \x1B[0;3;30;47mItalic WhiteBG Black Text"
let () = Format.printf "\o033[36mBlue Text \o033[0;3;30;47mItalic WhiteBG Black Text"
Dans tous les cas, on obtient le résultat suivant :

Que se passe-t-il, par contre, si j’exécute une de ces lignes dans un terminal non ANSI ? En testant sur TryOCaml:

On ne veut surtout pas que ce genre d’affichage puisse arriver. Il faudrait donc pouvoir s’assurer que le marquage du texte soit actif uniquement quand on le décide. L’idée de créer deux chaînes de formattage en fonction de notre capacité ou non à afficher du texte marqué n’est clairement pas une bonne pratique de programmation (changer une formulation demande de changer deux chaînes de formattage, le code est difficilement maintenable). Il faudrait donc un outil qui puisse faire un pré-traitement de notre chaîne de formattage pour lui ajouter des décorations.
Cet outil est déjà fourni par Format, ce sont les tags sémantiques.
III.2 Les tags sémantiques
Introduits par @{ et fermés par @}, comme les boîtes ils sont paramétrés par la construction <t> pour indiquer l’ouverture (et la fermeture) du tag t. Contrairement aux boîtes, les tags n’ont aucune signification pour l’imprimeur (on peut faire l’analogie avec les types de base d’OCaml que sont int, bool, float etc et les types définis par le programmeur ou la programmeuse (type t = A | B, par exemple. Les types de base ont déjà une quantité de fonctions qui leurs sont associés alors que les types définis ne signifient rien tant qu’on n’écrit pas les fonctions qui les manipuleront). L’avantage premier de ces tags est donc que, n’ayant aucune signification, ils sont tout simplement ignorés par l’imprimeur lors de l’affichage de notre chaîne de caractère finale:

Par défaut, l’imprimeur ne traite pas les tags sémantiques (ce qui
permet d’avoir un comportement d’affichage aussi simple que possible par
défaut). Le traitement des tags sémantiques peut être activé pour
chaque formatter indépendamment avec les fonctions val pp_set_tags : formatter -> bool -> unit, val pp_set_print_tags : formatter -> bool -> unit et val pp_set_mark_tags : formatter -> bool -> unit dont on verra les effets immédiatement. Voyons déjà ce qui se passe avec la fonction générale pp_set_tags qui combine les deux suivantes :

Que s’est-il passé ?
Une fois que le traitement des tags sémantiques est activé, quatre opérations vont être effectuées à chaque ouverture et fermeture de tag :
print_open_stagsuivie demark_open_stagpour chaque tagtouvert avec@{<t>mark_close_stagsuivie deprint_close_stagpour chaque tagtfermé avec@}correspondant à la dernière ouverture@{<t>
Regardons les signatures de ces quatre opérations :
type formatter_stag_functions = {
mark_open_stag : stag -> string;
mark_close_stag : stag -> string;
print_open_stag : stag -> unit;
print_close_stag : stag -> unit;
}
Les fonctions mark_*_stag prennent un tag sémantique en paramètre et renvoie une chaîne de caractères quand les fonctions print_*_stag prennent le même paramètre mais ne renvoient rien. La raison derrière est en réalité toute simple :
- Les fonctions de marquage écrivent directement dans la cible d’affichage (le terminal, le fichier ou autre)
- Les fonctions d’affichage écrivent dans le
formatterqui les traite comme des chaînes de caractères normales qui peuvent donc entraîner des sauts de ligne, des coupures, de nouvelles boîtes etc
Une indication de couleur pour un terminal ANSI n’apparaît pas à l’affichage, le texte se retrouve coloré, il semble donc naturel de ne pas vouloir que cette indication ait un effet sur l’impression élégante. En revanche, si on voulait avoir une sortie vers un fichier LaTeX ou HTML, cette indication de couleur apparaîtraît et devrait donc avoir une influence sur l’impression élégante.
Il est donc assez simple de savoir dans quel cas on veut utiliser print_*_stag ou mark_*_stag :
- Si le tag doit avoir un impact immédiat sur l’apparence du texte affiché (couleur, taille, décorations…) et non pas son contenu, il faut utiliser
mark_*_stag - Si le tag doit avoir un impact sur le contenu du texte affiché et non pas sur son apparence, il faut utiliser
print_*_stag - Si le tag doit avoir un impact à la fois sur le contenu et l’apparence du texte affiché alors il faut utiliser les deux en séparant bien entre contenu géré par
print_*_staget apparence gérée parmark_*_stag
Ces quatres fonctions ont chacune un comportement par défaut que voici :
let mark_open_stag = function
| String_tag s -> "<" ^ s ^ ">"
| _ -> ""
let mark_close_stag = function
| String_tag s -> "</" ^ s ^ ">"
let print_open_stag = ignore
let print_close_stag = ignore
Le type stag est un type somme extensible (introduits dans OCaml 4.02.0) c’est-à-dire qu’il est défini de la sorte
type stag = ..
type stag += String_tag of string
Par défaut seuls les String_tag of string sont donc reconnus comme des tags sémantiques (ce sont aussi les seuls qui peuvent être obtenus par la construction @{<t> ... @}, ici t sera traité comme String_tag t) ce qui est illustré par le comportement par défaut de mark_open_tag et mark_close_tag. Ce comportement par défaut nous permet aussi de comprendre ce qui est arrivé ici :

N’ayant pas personnalisé les opérations de manipulation des tags, leur comportement par défaut a été exécuté, ce qui revient à afficher directement le tag entre chevrons sans passer par le formatter. Il faut donc définir les comportements voulus pour nos tags (attention, ne manipulant que des chaînes de caractère, toute erreur est conséquemment difficile à identifier et corriger, il vaut mieux donc éviter les célèbres | _ -> () — il faudrait en réalité les éviter tout le temps si possible mais c’est une autre histoire).
Commençons donc par définir nos tags et ce à quoi on veut qu’ils correspondent :
open Format
type style =
| Normal
| Italic
| Italic_off
| FG_Black
| FG_Blue
| FG_Default
| BG_White
| BG_Default
let close_tag = function
| Italic -> Italic_off
| FG_Black | FG_Blue | FG_Default -> FG_Default
| BG_White | BG_Default -> BG_Default
| _ -> Normal
let style_of_tag = function
| String_tag s -> begin match s with
| "n" -> Normal
| "italic" -> Italic
| "/italic" -> Italic_off
| "fg_black" -> FG_Black
| "fg_blue" -> FG_Blue
| "fg_default" -> FG_Default
| "bg_white" -> BG_White
| "bg_default" -> BG_Default
| _ -> raise Not_found
end
| _ -> raise Not_found
Maintenant que chaque tag possible est géré, il nous faut les associer à leur valeur (ANSI dans ce cas) et implémenter nos propres fonctions de marquages (et pas d’affichage car a priori ces tags n’ont aucun effet sur le contenu du texte affiché) :
(* See https://en.wikipedia.org/wiki/ANSI_escape_code#SGR_parameters for some values *)
let to_ansi_value = function
| Normal -> "0"
| Italic -> "3"
| Italic_off -> "23"
| FG_Black -> "30"
| FG_Blue -> "34"
| FG_Default -> "39"
| BG_White -> "47"
| BG_Default -> "49"
let ansi_tag = Printf.sprintf "\x1B[%sm"
let start_mark_ansi_stag t = ansi_tag @@ to_ansi_value @@ style_of_tag t
let stop_mark_ansi_stag t = ansi_tag @@ to_ansi_value @@ close_tag @@ style_of_tag t
On se le rappelle, l’ouverture d’un tag ANSI se fait avec la séquence d’échappement x1B suivie de une ou plusieurs valeurs de tags séparées par ; entre [ et m. Dans notre cas chaque tag n’est associé qu’à une valeur mais il serait tout à fait possible d’avoir un Error -> "1;4;31" qui imposerait un affichage gras, souligné et en rouge. Tant que la chaîne de caractère renvoyée au terminal correspond bien à une séquence de marquage ANSI tout est possible.
Il faut ensuite faire en sorte que ces fonctions soient celles utilisées par le formatter lors de leur traitement :
let add_ansi_marking formatter =
let open Format in
pp_set_mark_tags formatter true;
let old_fs = pp_get_formatter_stag_functions formatter () in
pp_set_formatter_stag_functions formatter
{ old_fs with
mark_open_stag = start_mark_ansi_stag;
mark_close_stag = stop_mark_ansi_stag }
On utilise la fonction pp_set_mark_tags (au lieu de pp_set_tags) car on ne se sert pas de print_*_stags et on associe aux fonctions mark_*_stag les fonctions *_ansi_stag.
Il ne nous reste plus qu’à faire en sorte que les tags sémantiques soient traités et avec nos fonctions avant d’afficher notre chaîne de caractères :
let () =
add_ansi_marking std_formatter;
Format.printf "@{<fg_blue>Blue Text @}@{<italic>@{<bg_white>@{<fg_black>Italic WhiteBG BlackFG Text@}@}@}"
Et l’affichage dans le terminal sera bien celui voulu :

Si le programme doit être affiché dans un terminal non ANSI il suffit simplement d’enlever la ligne add_ansi_marking std_formatter; :

On pourrait aussi faire en sorte que notre texte puisse être envoyé vers un document HTML.
Il faut déjà changer les valeurs associées aux tags (on voit ici l’utilisation de boîtes verticales à indentation nulle mentionnée lors du paragraphe sur les boîtes structurelles) :
let to_html_value fmt =
let fg_color c = Format.fprintf fmt {|@[<v 0>@[<v 2><span style="color:%s;">@,|} c in
let bg_color c = Format.fprintf fmt {|@[<v 0>@[<v 2><span style="background-color:%s;">@,|} c in
let close_span () = Format.fprintf fmt "@]@,</span>@]" in
let default = Format.fprintf fmt in
fun t -> match t with
| Normal -> ()
| Italic -> default "<i>"
| Italic_off -> default "</i>"
| FG_Black -> fg_color "black"
| FG_Blue -> fg_color "blue"
| FG_Default -> close_span ()
| BG_White -> bg_color "white"
| BG_Default -> close_span ()
La construction {| ... |} permet d’avoir des chaînes de caractères sans les caractères spéciaux " et `` ce qui permet d’écrire {|"This is a nice "|} sans espacer ces caractères.
De même, la construction
let fonction arg1 ... argn =
let expr1 = ... in
...
let exprn = ... in
fun argn1 ... argnm ->
Permet de définir des expressions internes à une fonction qui
dépendent des arguments fournis avant et donc, dans le cas d’une
application partielle, de calculer cet environnement une seule fois.
Dans le cas de la fonction to_html_value je pourrai donc créer la nouvelle application partielle let to_html_value_std = to_html_value std_formatter qui contiendra donc directment les implémentations de fg_color, bg_color, close_span et default pour std_formatter.
Contrairement au cas du terminal ANSI, ce qui changera sera le
contenu et non pas l’apparence du texte, nous utiliserons donc les
fonctions print_*_stag. C’est pourquoi nos fonctions doivent directement écrire dans le formatter et non pas renvoyer une chaîne de caractères.
Les fonctions d’ouverture et de fermeture ne changent pas énormément :
let start_print_html_stag fmt t =
to_html_value fmt @@ style_of_tag t
let stop_print_html_stag fmt t =
to_html_value fmt @@ close_tag @@ style_of_tag t
On associe ensuite ces fonctions aux fonctions print_*_stag :
let add_html_printings formatter =
let open Format in
pp_set_mark_tags formatter false;
pp_set_print_tags formatter true;
let old_fs = pp_get_formatter_stag_functions formatter () in
pp_set_formatter_stag_functions formatter
{ old_fs with
print_open_stag = start_print_html_stag formatter;
print_close_stag = stop_print_html_stag formatter}
On en profite pour désactiver le marquage sur le formatter passé en paramètre. Cela évite d’avoir de mauvaises surprises au cas où il aurait été activé précédemment (il aurait fallu faire de même lors du marquage pour le terminal ANSI).
Finalement, l’appel à :
let () =
add_html_printings std_formatter;
Format.printf "@[<v 0>@{<fg_blue>Blue Text @}@,@{<italic>@{<bg_white>@{<fg_black>Italic WhiteBG BlackFG Text@}@}@}@]@."
Nous donne le résultat attendu :
<span style="color:blue;">
Blue Text
</span>
<i>
<span style="background-color:white;">
<span style="color:black;">
Italic WhiteBG BlackFG Text
</span>
</span>
</i>
Conclusion
Nous voici arrivés à la fin de ce tutoriel qui, je l’espère, vous permettra d’appréhender le module Format avec bien plus de sérénité.
Dans les possibilités non présentées ici mais qu’il est intéressant d’avoir en mémoire :
- Possibilité de redéfinir intégralement toutes les fonctions d’affichage définies dans l’enregistrement :
<span class="hljs-keyword">type</span>
formatter_out_functions = {
out_string :
<span class="hljs-built_in">string</span> -> <span class="hljs-built_in">int</span> -> <span class="hljs-built_in">int</span> -> <span class="hljs-built_in">unit</span>;
out_flush :
<span class="hljs-built_in">unit</span> -> <span class="hljs-built_in">unit</span>;
out_newline :
<span class="hljs-built_in">unit</span> -> <span class="hljs-built_in">unit</span>;
out_spaces :
<span class="hljs-built_in">int</span> -> <span class="hljs-built_in">unit</span>;
out_indent :
<span class="hljs-built_in">int</span> -> <span class="hljs-built_in">unit</span>;
}
- Possibilité de transformer n’importe quel sortie en un formatter pour écrire directement dedans sans avoir à passer par des chaînes de caractère intermédiaire (notamment la fonction
val formatter_of_buffer : Buffer.t -> formatterqui permet directement d’écrire dans un buffer - L’impression élégante symbolique qui imprime de façon symbolique donc permet de voir directement quelles directives seront envoyées au
formatterà l’impression. Très utile pour débuguer en cas d’impression cacophonique mais aussi extrêmement puissant pour effectuer une phase de post-traitement (par exemple si on veut ajouter un symbole à chaque début de ligne) - Les fonctions utiles qu’il ne faut pas oublier d’utiliser (je sais que les devs OCaml aiment réinventer la roue mais il existe déjà des fonctions pour afficher des listes, des options et les résultats
Ok _ | Error _) :
val pp_print_list : ?pp_sep:(formatter -> unit -> unit) -> (formatter -> 'a -> unit) -> formatter -> 'a list -> unit
(* Affiche une liste dont chaque élément est séparé par le séparateur par défaut `@,` ou celui fourni *)
val pp_print_option : ?none:(formatter -> unit -> unit) -> (formatter -> ‘a -> unit) -> formatter -> ‘a option -> unit
(* Affiche le contenu d’une option en cas de Some contenu et rien par défaut si None ou l’affichage fourni *)</p>
val pp_print result : ok:(formatter -> ‘a -> unit) -> error:(formatter -> ‘e -> unit) -> formatter -> (‘a, ‘e) result -> unit
(* Affiche le contenu d’un result. Les arguments ne sont ici pas optionnels et conditionnent l’affichage en cas de Ok </em> et de Error _ *)
- Enfin, une pelletée de fonctions à la
printftelles que, donc : fprintfque nous avons déjà vuedprintfqui permet de retarder l'évaluation de l'impression et donc de ne pas calculer des impressions qui ne seront jamais faitesifprintfqui n'affiche rien (utile lorsqu'on veut avoir la même signature quefprintfmais en étant sûr que rien ne sera fait)
Sources :
-
Tutoriel du site OCaml
-
Richard Bonichon, Pierre Weis. Format Unraveled. 28ièmes Journées Francophones des LangagesApplicatifs, Jan 2017, Gourette, France. hal-01503081
Codes sources :
Code LaTeX correspondant à printf
\documentclass[tikz,border=10pt]{standalone}
\usepackage{tikz}
\usetikzlibrary{math}
\usetikzlibrary{tikzmark}
\usepackage{xcolor}
\pagecolor[rgb]{0,0,0}
\color[rgb]{1,1,1}
\colorlet{color1}{blue!50!white}
\colorlet{color2}{red!50!white}
\colorlet{color3}{green!50!black}
\begin{document}
\begin{tikzpicture}[remember picture]
\node [align=left,font=\ttfamily] at (0,0) {
let s = "toto" in\[2em]
printf "{color{color1}\tikzmarknode{scd}{\%d}}
{color{color2}\tikzmarknode{scc}{\%c}}
{color{color3}\tikzmarknode{scs}{\%s}}"
{\color{color1}\tikzmarknode{d}{3}}
{\color{color2}\tikzmarknode{c}{'c'}}
{\color{color3}\tikzmarknode{s}{s}}\\[2em]
> "3 c toto"
};
\draw[<-, color1] (scd.north) -- ++(0,0.5) -| (d);
\draw[<-, color2] (scc.south) -- ++(0,-0.4) -| (c);
\draw[<-, color3] (scs.north) -- ++(0,0.4) -| (s);
\end{tikzpicture}
end{document}
Code LaTeX correspondant à fprintf:
\documentclass[tikz,border=10pt]{standalone}
\usepackage{tikz}
\usetikzlibrary{math}
\usetikzlibrary{decorations.pathreplacing,tikzmark}
\usepackage{xcolor}
\pagecolor[rgb]{0,0,0}
\color[rgb]{1,1,1}
\colorlet{color1}{blue!50!white}
\colorlet{color2}{red!50!white}
\colorlet{color3}{green!50!black}
\begin{document}
\begin{tikzpicture}[remember picture]
\node [align=left,font=\ttfamily] at (0,0) {
let s = "toto" in\\[2em]
fprintf \tikzmarknode{fmt}{fmt} \tikzmarknode{str}{"{\color{color1}\tikzmarknode{scd}{\%d}}
{\color{color2}\tikzmarknode{scc}{\%c}}
{\color{color3}\tikzmarknode{scs}{\%s}}"}
{\color{color1}\tikzmarknode{d}{3}}
{\color{color2}\tikzmarknode{c}{'c'}}
{\color{color3}\tikzmarknode{s}{s}}\\[2em]
> \\
(* fmt <- "3 c toto" *)
};
\draw[<-, color1] (scd.north) -- ++(0,0.5) -| (d);
\draw[<-, color2] (scc.south) -- ++(0,-0.3) -| (c);
\draw[<-, color3] (scs.north) -- ++(0,0.4) -| (s);
\draw[decorate,decoration={brace, amplitude=5pt, raise=10pt},yshift=-2cm] (str.south east) -- (str.south west) node[midway, yshift=-13pt](a){} ;
\draw[->, white] (a.south) -- ++(0,-0.1) -| (fmt);
\end{tikzpicture}
\end{document}
Code LaTeX correspondant à fprintf avec utilisation de %a
\documentclass[tikz,border=10pt]{standalone}
\usepackage{tikz}
\usetikzlibrary{math}
\usetikzlibrary{decorations.pathreplacing,tikzmark}
\usepackage{xcolor}
\pagecolor[rgb]{0,0,0}
\color[rgb]{1,1,1}
\colorlet{color1}{blue!50!white}
\colorlet{color2}{red!50!white}
\colorlet{color3}{green!50!black}
\begin{document}
\begin{tikzpicture}[remember picture]
\node [align=left,font=\ttfamily] at (0,0) {
let s = "toto" in\\[2em]
type expr = \{i: int; j: int\}\\
let pp\_expr fmt {i; j} = fprintf fmt "<\%d, \%d> i j" in\\[2em]
fprintf \tikzmarknode{fmt}{std\_formatter} \tikzmarknode{str}{"{\color{color1}\tikzmarknode{scd}{\%d}}
{\color{color2}\tikzmarknode{sca}{\%a}}
{\color{color3}\tikzmarknode{scs}{\%s}}"}
{\color{color1}\tikzmarknode{d}{3}}
{\color{color2}\tikzmarknode{ppe}{pp\_expr}}
{\color{color2}\tikzmarknode{e}{\{i=1; j=2\}}}
{\color{color3}\tikzmarknode{s}{s}}\\[2em]
> "3 <1, 2> toto"
};
\draw[<-, color1] (scd.north) -- ++(0,0.5) -| (d);
\draw[<-, color2] (sca.south) -- ++(0,-0.3) -| (ppe);
\draw[<-, color2] (sca.65) -- ++(0,0.3) -| (e);
\draw[->, color2] (fmt.north) -- ++(0,0.2) -| (sca.115);
\draw[<-, color3] (scs.south) -- ++(0,-0.4) -| (s);
\draw[decorate,decoration={brace, amplitude=5pt, raise=12pt},yshift=-2cm] (str.south east) -- (str.south west) node[midway, yshift=-13pt](a){} ;
\draw[->, white] (a.south) -- ++(0,-0.1) -| (fmt);
\end{tikzpicture}
\end{document}
About OCamlPro:
OCamlPro is a R&D lab founded in 2011, with the mission to help industrial users benefit from experts with a state-of-the-art knowledge of programming languages theory and practice.
- We provide audit, support, custom developer tools and training for both the most modern languages, such as Rust, Wasm and OCaml, and for legacy languages, such as COBOL or even home-made domain-specific languages;
- We design, create and implement software with great added-value for our clients. High complexity is not a problem for our PhD-level experts. For example, we helped the French Income Tax Administration re-adapt and improve their internally kept M language, we designed a DSL to model and express revenue streams in the Cinema Industry, codename Niagara, and we also developed the prototype of the Tezos proof-of-stake blockchain from 2014 to 2018.
- We have a long history of creating open-source projects, such as the Opam package manager, the LearnOCaml web platform, and contributing to other ones, such as the Flambda optimizing compiler, or the GnuCOBOL compiler.
- We are also experts of Formal Methods, developing tools such as our SMT Solver Alt-Ergo (check our Alt-Ergo Users' Club) and using them to prove safety or security properties of programs.
Please reach out, we'll be delighted to discuss your challenges: contact@ocamlpro.com or book a quick discussion.
Most Recent Articles
2025
2024
- opam 2.3.0 release!
- Optimisation de Geneweb, 1er logiciel français de Généalogie depuis près de 30 ans
- Alt-Ergo 2.6 is Out!
- Flambda2 Ep. 3: Speculative Inlining
- opam 2.2.0 release!
- Flambda2 Ep. 2: Loopifying Tail-Recursive Functions
- Fixing and Optimizing the GnuCOBOL Preprocessor
- OCaml Backtraces on Uncaught Exceptions
- Opam 102: Pinning Packages
- Flambda2 Ep. 1: Foundational Design Decisions
- Behind the Scenes of the OCaml Optimising Compiler Flambda2: Introduction and Roadmap
- Lean 4: When Sound Programs become a Choice
- Opam 101: The First Steps
2023