Reduced Memory Allocations with ocp-memprof
In this blog post, we explain how ocp-memprof helped us identify a piece of code in Alt-Ergo that needed to be improved. Simply put, a function that merges two maps was performing a lot of unnecessary allocations, negatively impacting the garbage collector's activity. A simple patch allowed us to prevent these allocations, and thus speed up Alt-Ergo's execution.
The Story
Il all started with a challenging example coming from an industrial user of Alt-Ergo, our SMT solver. It was proven by Alt-Ergo in approximately 70 seconds. This seemed abnormnally long and needed to be investigated. Unfortunately, all our tests with different options (number of triggers, case-split analysis, …) and different plugins (satML plugin, profiling plugin, fm-simplex plugin) of Alt-Ergo failed to improve the resolution time. We then profiled an execution using ocp-memprof to understand the memory behavior of this example.
Profiling an Execution with ocp-memprof
As usual, profiling an OCaml application with ocp-memprof is very simple (see the user manual for more details). We just compiled Alt-Ergo in the OPAM switch for ocp-memprof (version 4.01.0+ocp1) and executed the following command:
$ ocp-memprof -exec ./ae-4.01.0+ocp1-public-without-patch pb-many-GCs.why
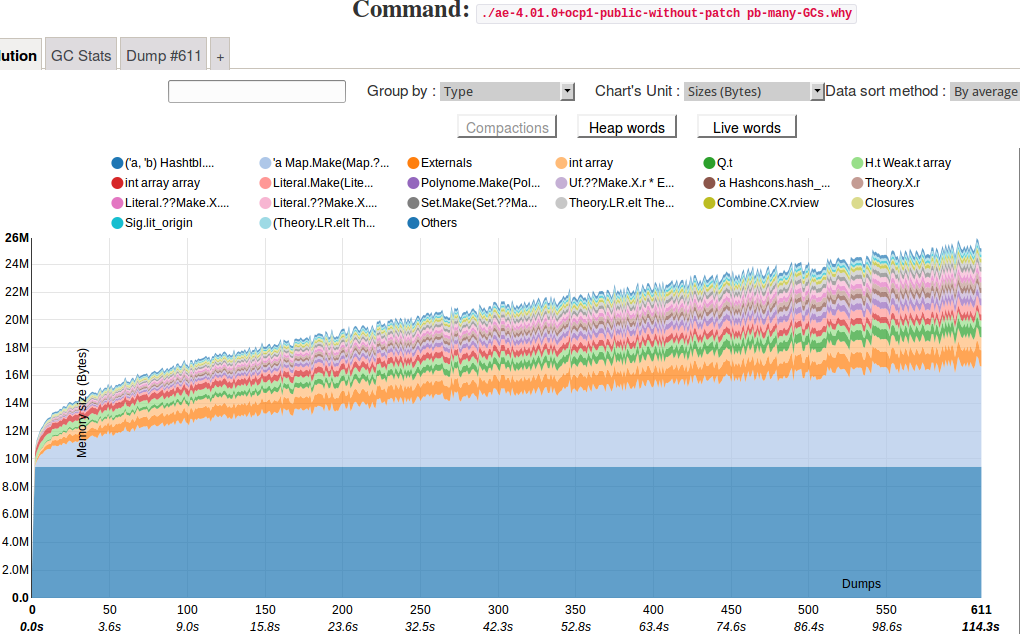
The execution above triggers 612 garbage collections in about 114 seconds. The analysis of the generated dumps produces the evolution graph below. We notice on the graph that:
- we have approximately 10 MB of hash-tables allocated since the beginning of the execution, which is expected;
- the second most allocated data in the major heap are maps, and they keep growing during the execution of Alt-Ergo.
We are not able to precisely identify the allocation origins of the maps in this graph (maps are generic structures that are intensively used in Alt-Ergo). To investigate further, we wanted to know if some global value was abnormally retaining a lot of memory, or if some (non recursive-terminal) iterator was causing some trouble when applied on huge data structures. For that, we extended the analysis with the --per-root option to focus on the memory graph of the last dump. This is done by executing the following command, where 4242 is the PID of the process launched by ocp-memprof --exec in the previous command:
$ ocp-memprof -load 4242 -per-root 611
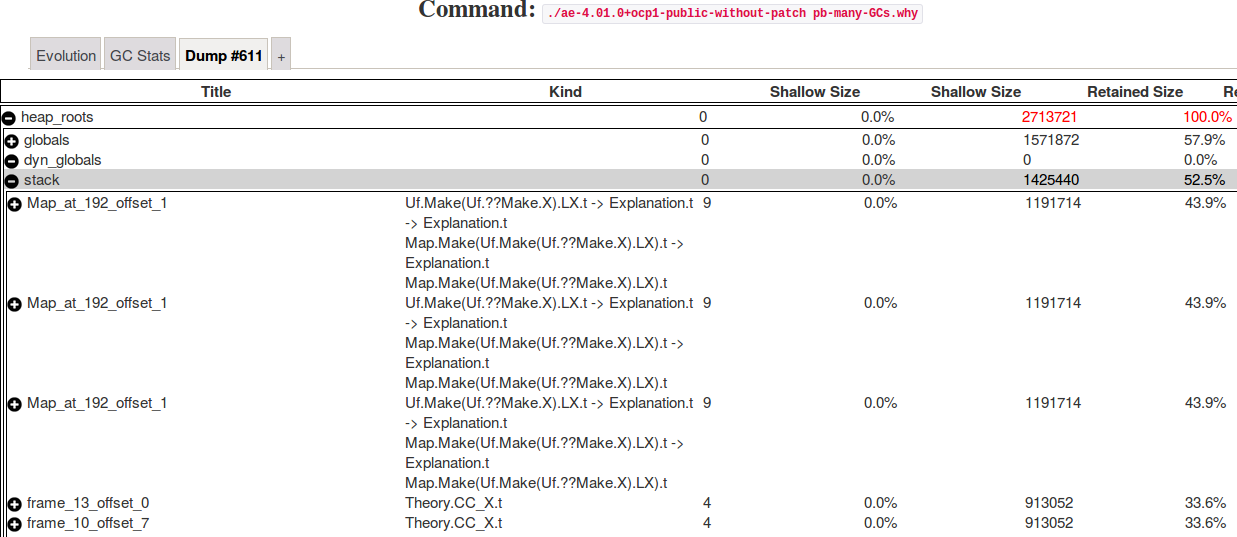
The per-root graph (above, on the right) gives more interesting information. When expanding the stack node and sorting the sixth column in decreasing order, we notice that:
- a bunch of these maps are still in the stack: the item
Map_at_192_offset_1in the first column means that most of the memory is retained by thefoldfunction, at line 192 of theMapmodule (resolution of stack frames is only available in the commercial version ofocp-memprof); - the "kind" column corresponding to
Map_at_192_offset_1gives better information. It provides the signature of the function passed to fold. This information is already provided by the online version.
Uf.Make(Uf.??Make.X).LX.t ->;
Explanation.t ->;
Explanation.t Map.Make(Uf.Make(Uf.??Make.X).LX).t ->;
Explanation.t Map.Make(Uf.Make(Uf.??Make.X).LX).t
This information allows us to see the precise origin of the allocation: the map of module LX used in uf.ml. Lucky us, there is only one fold function of LX's maps in the Uf module with the same type.
Optimizing the Code
Thanks to the information provided by the --per-root option, we identified the code responsible for this behavior:
(*** function extracted from module uf.ml ***)
module MapL = Map.Make(LX)
let update_neqs r1 r2 dep env =
let merge_disjoint_maps l1 ex1 mapl =
try
let ex2 = MapL.find l1 mapl in
let ex = Ex.union (Ex.union ex1 ex2) dep in
raise (Inconsistent (ex, cl_extract env))
with Not_found ->;
MapL.add l1 (Ex.union ex1 dep) mapl
in
let nq_r1 = lookup_for_neqs env r1 in
let nq_r2 = lookup_for_neqs env r2 in
let mapl = MapL.fold merge_disjoint_maps nq_r1 nq_r2 in
MapX.add r2 mapl (MapX.add r1 mapl env.neqs)
Roughly speaking, the function above retrieves two maps nq_r1 and nq_r2 from env, and folds on the first one while providing the second map as an accumulator. The local function merge_disjoint_maps (passed to fold) raises Exception.Inconsistent if the original maps were not disjoint. Otherwise, it adds the current binding (after updating the corresponding value) to the accumulator. Finally, the result mapl of the fold is used to update the values of r1 and r2 in env.neqs.
After further debugging, we observed that one of the maps (nq_r1 and nq_r2) is always empty in our situation. A straightforward fix consists in testing whether one of these two maps is empty. If it is the case, we simply return the other map. Here is the corresponding code:
(*** first patch: testing if one of the maps is empty ***)
…
let mapl =
if MapL.is_empty nq_r1 then nq_r2
else
if MapL.is_empty nq_r2 then nq_r1
else MapL.fold_merge merge_disjoint_maps nq_r1 nq_r2
…
Of course, a more generic solution should not just test for emptiness, but should fold on the smallest map. In the second patch below, we used a slightly modified version of OCaml's maps that exports the height function (implemented in constant time). This way, we always fold on the smallest map while providing the biggest one as an accumulator.
(*** second (better) patch : folding on the smallest map ***)
…
let small, big =
if MapL.height nq_r1 > MapL.height nq_r2 then nq_r1, nq_r2
else nq_r2, nq_r1
in
let mapl = MapL.fold merge_disjoint_maps small big in
…
Checking the Efficiency of our Patch
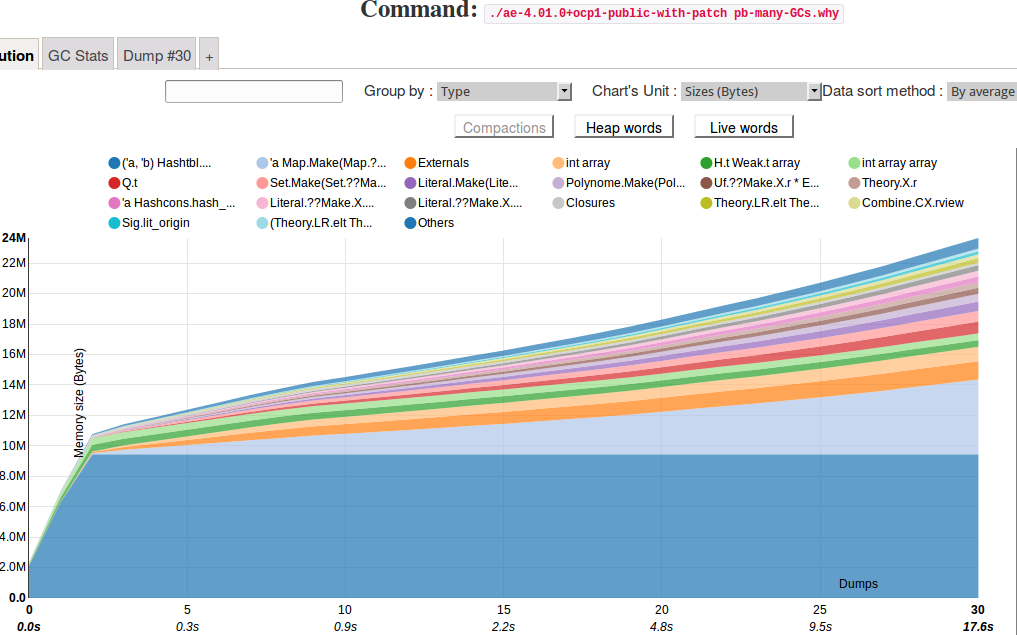
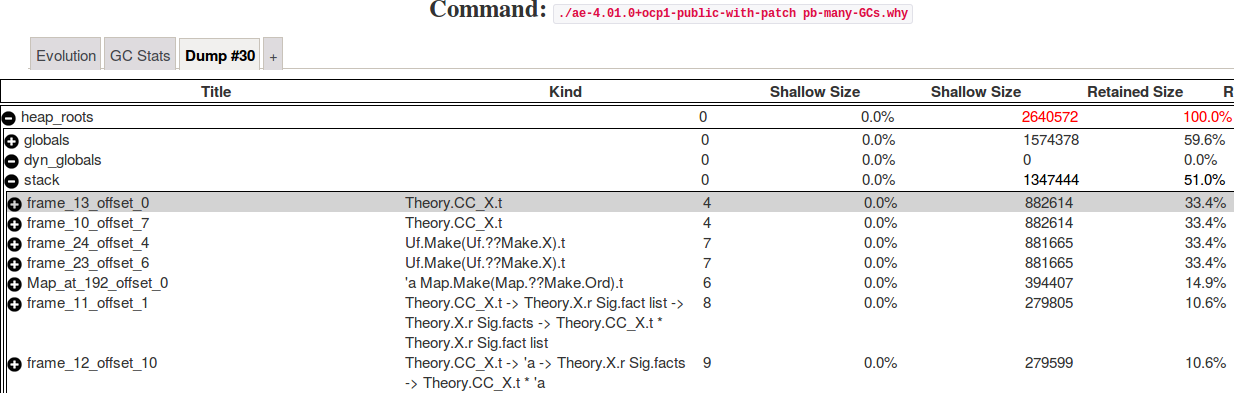
Curious to see the result of the patch ? We regenerate the evolution and memory graphs of the patched code (fix 1), and we noticed:
- a better resolution time: from 69 seconds to 16 seconds;
- less garbage collection : from 53,000 minor collections to 19,000;
- a smaller memory footprint : from 26 MB to 24 MB;
Conclusion
We show in this post that ocp-memprof can also be used to optimize your code, not only by decreasing memory usage, but by improving the speed of your application. The interactive graphs are online in our gallery of examples if you want to see and explore them (without the patch and with the patch).
| AE | AE + patch | Remarks | |
|---|---|---|---|
| 4.01.0 | 69.1 secs | 16.4 secs | substantial improvement on the example |
| 4.01.0+ocp1 | 76.3 secs | 17.1 secs | when using the patched version of Alt-Ergo |
| dumps generation | 114.3 secs (+49%) | 17.6 secs (+2.8%) | (important) overhead when dumping memory snapshots |
| # dumps (major collections) | 612 GCs | 31 GCs | impressive GC activity without the patch |
| dumps analysis (online ocp-memprof) |
759 secs | 24.3 secs | |
| dumps analysis (commercial ocp-memprof) |
153 secs | 3.7 secs | analysis with commercial ocp-memprof is **~ x5 faster** than public version (above) |
| AE memory footprint | 26 MB | 24 MB | memory consumption is comparable |
| minor collections | 53K | 19K | fewer minor GCs thanks to the patch |
More information:
- Homepage: https://memprof.typerex.org/
- Gallery of examples: https://memprof.typerex.org/gallery.php
- Free Version: https://memprof.typerex.org/free-version.php
- Commercial Version: https://memprof.typerex.org/commercial-version.php
- Report a Bug: https://memprof.typerex.org/report-a-bug.php
About OCamlPro:
OCamlPro is a R&D lab founded in 2011, with the mission to help industrial users benefit from experts with a state-of-the-art knowledge of programming languages theory and practice.
- We provide audit, support, custom developer tools and training for both the most modern languages, such as Rust, Wasm and OCaml, and for legacy languages, such as COBOL or even home-made domain-specific languages;
- We design, create and implement software with great added-value for our clients. High complexity is not a problem for our PhD-level experts. For example, we helped the French Income Tax Administration re-adapt and improve their internally kept M language, we designed a DSL to model and express revenue streams in the Cinema Industry, codename Niagara, and we also developed the prototype of the Tezos proof-of-stake blockchain from 2014 to 2018.
- We have a long history of creating open-source projects, such as the Opam package manager, the LearnOCaml web platform, and contributing to other ones, such as the Flambda optimizing compiler, or the GnuCOBOL compiler.
- We are also experts of Formal Methods, developing tools such as our SMT Solver Alt-Ergo (check our Alt-Ergo Users' Club) and using them to prove safety or security properties of programs.
Please reach out, we'll be delighted to discuss your challenges: contact@ocamlpro.com or book a quick discussion.
Most Recent Articles
2025
2024
- opam 2.3.0 release!
- Optimisation de Geneweb, 1er logiciel français de Généalogie depuis près de 30 ans
- Alt-Ergo 2.6 is Out!
- Flambda2 Ep. 3: Speculative Inlining
- opam 2.2.0 release!
- Flambda2 Ep. 2: Loopifying Tail-Recursive Functions
- Fixing and Optimizing the GnuCOBOL Preprocessor
- OCaml Backtraces on Uncaught Exceptions
- Opam 102: Pinning Packages
- Flambda2 Ep. 1: Foundational Design Decisions
- Behind the Scenes of the OCaml Optimising Compiler Flambda2: Introduction and Roadmap
- Lean 4: When Sound Programs become a Choice
- Opam 101: The First Steps
2023